Glossary term
Glossary term
Architecture
A neural network layer that transforms a sequence of embeddings (for example, token embeddings) into another sequence of embeddings. Each embedding in the output sequence is constructed by integrating information from the elements of the input sequence through an attention mechanism.
The self part of self-attention refers to the sequence attending to itself rather than to some other context. Self-attention is one of the main building blocks for Transformers and uses dictionary lookup terminology, such as "query", "key", and "value".
A self-attention layer starts with a sequence of input representations, one for each word. The input representation for a word can be a simple embedding. For each word in an input sequence, the network scores the relevance of the word to every element in the whole sequence of words. The relevance scores determine how much the word's final representation incorporates the representations of other words.
For example, consider the following sentence:
The animal didn't cross the street because it was too tired.
The following illustration (from Transformer: A Novel Neural Network Architecture for Language Understanding) shows a self-attention layer's attention pattern for the pronoun it, with the darkness of each line indicating how much each word contributes to the representation:
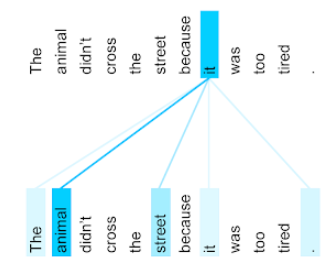
The self-attention layer highlights words that are relevant to "it". In this case, the attention layer has learned to highlight words that it might refer to, assigning the highest weight to animal.
For a sequence of n tokens, self-attention transforms a sequence of embeddings n separate times, once at each position in the sequence.
Refer also to attention and multi-head self-attention.
For example, consider the following sentence:
The animal didn't cross the street because it was too tired.
Created for this library
A document understanding team uses self-attention layers in its long-context contract reader to capture dependencies between clauses regardless of position.
An NLP research team analyzes self-attention patterns to study which token relationships the model relies on.
A code-completion vendor uses self-attention so the model can use earlier function signatures when predicting later tokens.
Definition source: Google for Developers Machine Learning Glossary | Creative Commons Attribution 4.0 License