Glossary term
Glossary term
Evaluation and Benchmarks
An algorithm for predicting a model's ability to generalize to new data. The k in k-fold refers to the number of equal groups you divide a dataset's examples into; that is, you train and test your model k times. For each round of training and testing, a different group is the test set, and all remaining groups become the training set. After k rounds of training and testing, you calculate the mean and standard deviation of the chosen test metric(s).
For example, suppose your dataset consists of 120 examples. Further suppose, you decide to set k to 4. Therefore, after shuffling the examples, you divide the dataset into four equal groups of 30 examples and conduct four training and testing rounds:
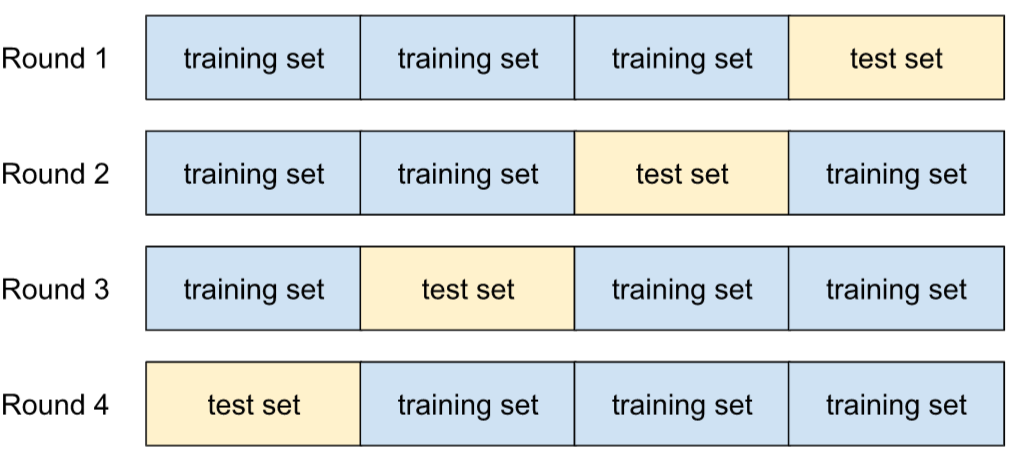
For example, Mean Squared Error (MSE) might be the most meaningful metric for a linear regression model. Therefore, you would find the mean and standard deviation of the MSE across all four rounds.
For example, suppose your dataset consists of 120 examples. Further suppose, you decide to set k to 4. Therefore, after shuffling the examples, you divide the dataset into four equal groups of 30 examples and conduct four training and testing rounds:
For example, Mean Squared Error (MSE) might be the most meaningful metric for a linear regression model. Therefore, you would find the mean and standard deviation of the MSE across all four rounds.
Created for this library
A pricing analytics team uses 5-fold cross-validation to compare candidate models on small datasets before locking the choice for production.
A medical research team uses 10-fold cross-validation to estimate model performance more stably on a small clinical dataset.
A churn modeling team uses k-fold cross-validation on a stratified split so each fold has the same proportion of churned customers.
Definition source: Google for Developers Machine Learning Glossary | Creative Commons Attribution 4.0 License